OpenAIのAPIを使用しています。正確性の保証はできませんので、ご注意ください。
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) の概要
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) は、データポイントの密度に基づいてクラ�スタを形成するアルゴリズムです。特にノイズのあるデータに対して強力です。この方法は、データセット内の密度の高い領域を見つけ、これらの領域をクラスタとして識別し、低密度領域をノイズとして扱います。科学文献の中で最も引用されており、1996 年に Martin Ester、Hans-Peter Kriegel、Jörg Sander、Xiaowei Xu によって提案されました。
ユースケース
- 異常検知: 通常のデータが密なクラスタを形成し、異常値が孤立している場合、DBSCAN は異常値をノイズとして識別することができます。
- 画像セグメンテーション: 画像の領域を同じ特性を持つピクセルのクラスタとしてグループ化します。
- 地理空間データの分析: 地図上での物理的なグループ(例えば、都市や地域内のビル群)をクラスタとして識別します。
詳細
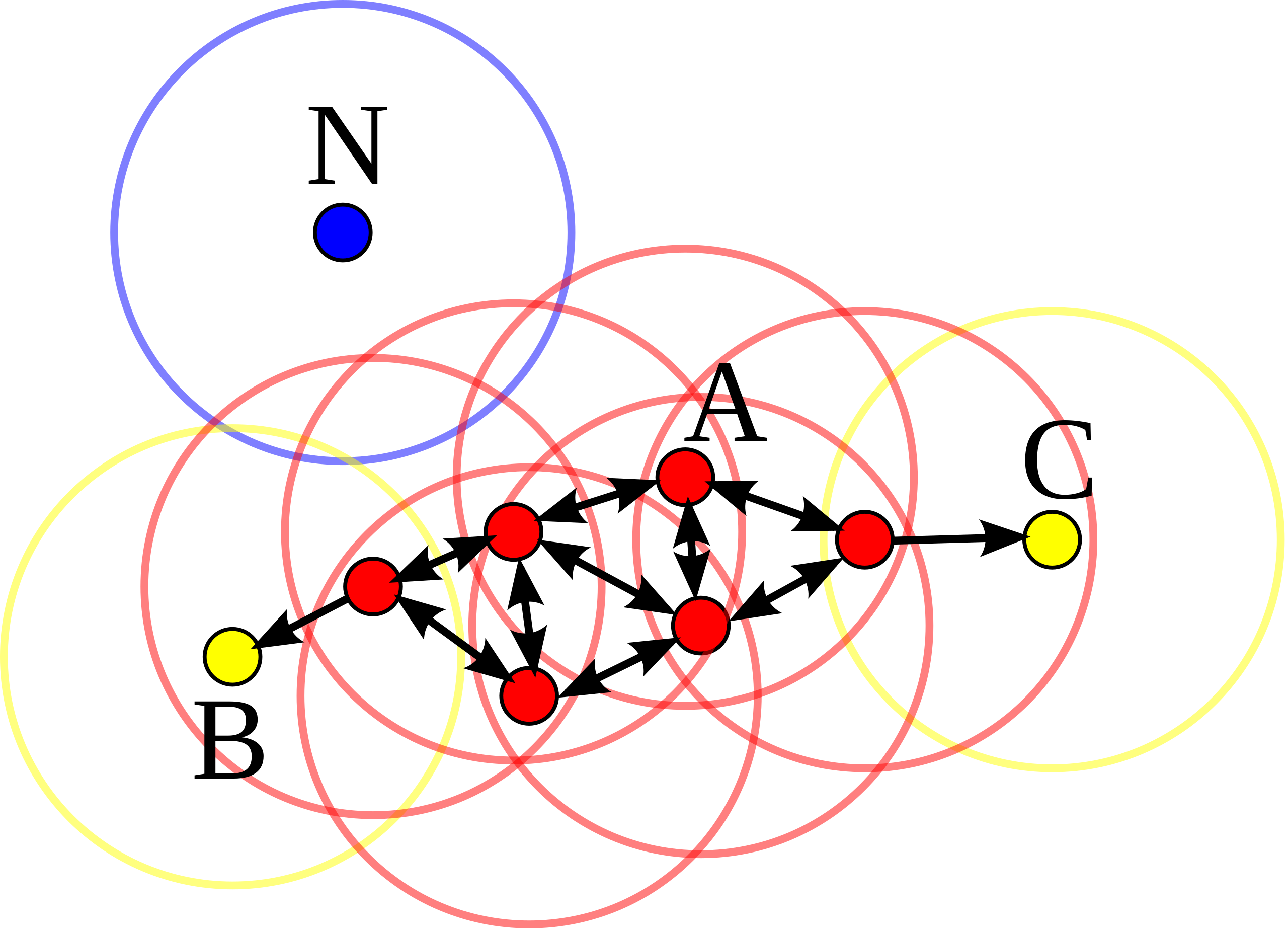
DBSCAN は以下のような手順で動作します。
-
初期化: アルゴリズムは未訪問のデータポイントから開始します。
-
半径 ε 内の隣接ポイントの検索: あるデータポイントを選択すると、半径 ε 内にある隣接するポイントを探索します。
-
拡張: 隣接ポイントの数が min_samples よりも多い場合、新しいクラスタが始まります。そのポイントはコアポイントとしてマークされ、隣接するポイントもこのクラスタに追加されます。このプロセスは再帰的に継続され、隣接するポイントがコアポイントの条件を満たす場合、それらの隣接するポイントもクラスタに追加されます。
-
ノイズの識別: min_samples よりも少ない隣接ポイントしかないデータポイントはノイズとしてマークされます。
-
新しい未訪問のポイントへ: すべての隣接ポイントが訪問されると、新しい未訪問のデータポイントが選択され、上記のプロセスが繰り返されます。
パラメータ
- ε (eps): このパラメータは、あるデータポイントの近隣を定義するための距離です。小さすぎると多くのデータポイントがノイズとしてマークされ、大きすぎるとクラスタが結合される可能性があります。
- min_samples: コアポイントとしてデータポイントを定義するために必要な隣接ポイントの最小数です。この数が大きいほど、より多くのポイントがノ�イズとしてマークされます。
キーポイント
- コアポイント: 半径 ε 内に min_samples 以上の隣接ポイントがあるデータポイント。
- 境界ポイント: 半径 ε 内に min_samples 未満の隣接ポイントがあり、しかし、コアポイントの近隣に存在するデータポイント。
- ノイズポイント: コアポイントでも境界ポイントでもないデータポイント。
長所
- クラスタの形を前提としない: DBSCAN は、k-means のようにクラスタが円形であるとは限らないため、さまざまな形状のクラスタを検出することができます。
- クラスタ数を指定する必要がない: 他のクラスタリングメソッドと異なり、クラスタ数をあらかじめ指定する必要がありません。
短所
- 密度の定義に依存: 適切な密度(ε の選択や最小のポイント数)を設定するのは難しい場合もあります。
- クラスタの密度が均一でない場合は難しい: クラスタ間の密度が大きく異なるデータセットに対しては、一つのパラメータ設定で適切にクラスタリングを行うことが難しい場合があります。
Python での実装
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import numpy as np
# データの生成 (ここでは適当なデータを利用)
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
# DBSCAN の適用
db = DBSCAN(eps=0.3, min_samples=5, metric='euclidean')
y_db = db.fit_predict(X)
# プロット
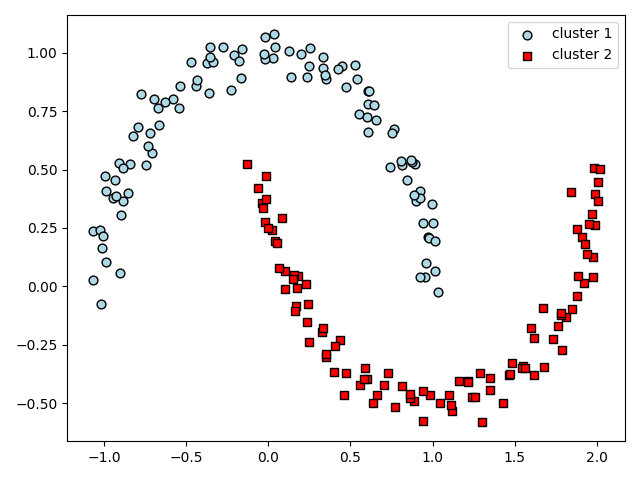
plt.scatter(X[y_db == 0, 0], X[y_db == 0, 1], c='lightblue', marker='o', s=40, edgecolor='black', label='cluster 1')
plt.scatter(X[y_db == 1, 0], X[y_db == 1, 1], c='red', marker='s', s=40, edgecolor='black', label='cluster 2')
plt.legend()
plt.tight_layout()
plt.show()
上記のコードは、DBSCAN アルゴリズムを利用して、データポイントをクラスタリングし、その結果をプロットする基本的な例です。eps は個々のポイントからの「近さ」を定義し、min_samples はコアポイントを形成するのに必要な最小ポイント数を定義します。
これで、形状が異なるクラスタがどのように分割されるかを視覚的に理解することができます。